Note
This page was generated from docs/tutorials/06_basket_option_pricing.ipynb.
Pricing Basket Options#
Introduction#
Suppose a basket option with strike price \(K\) and two underlying assets whose spot price at maturity \(S_T^1\), \(S_T^2\) follow given random distributions. The corresponding payoff function is defined as:
In the following, a quantum algorithm based on amplitude estimation is used to estimate the expected payoff, i.e., the fair price before discounting, for the option:
The approximation of the objective function and a general introduction to option pricing and risk analysis on quantum computers are given in the following papers:
[1]:
import matplotlib.pyplot as plt
from scipy.interpolate import griddata
%matplotlib inline
import numpy as np
from qiskit import QuantumRegister, QuantumCircuit, AncillaRegister, transpile
from qiskit_algorithms import IterativeAmplitudeEstimation, EstimationProblem
from qiskit.circuit.library import WeightedAdder, LinearAmplitudeFunction
from qiskit_aer.primitives import Sampler
from qiskit_finance.circuit.library import LogNormalDistribution
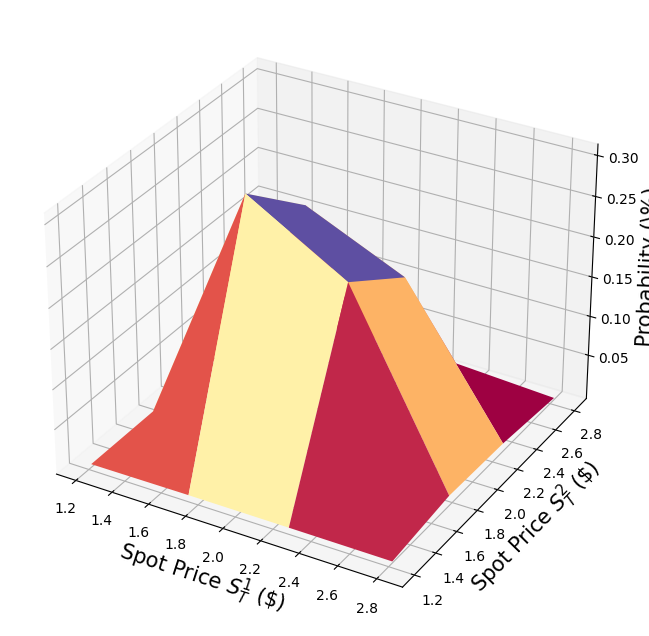
Uncertainty Model#
We construct a circuit to load a multivariate log-normal random distribution into a quantum state on \(n\) qubits. For every dimension \(j = 1,\ldots,d\), the distribution is truncated to a given interval \([\text{low}_j, \text{high}_j]\) and discretized using \(2^{n_j}\) grid points, where \(n_j\) denotes the number of qubits used to represent dimension \(j\), i.e., \(n_1+\ldots+n_d = n\). The unitary operator corresponding to the circuit implements the following:
where \(p_{i_1\ldots i_d}\) denote the probabilities corresponding to the truncated and discretized distribution and where \(i_j\) is mapped to the right interval using the affine map:
For simplicity, we assume both stock prices are independent and identically distributed. This assumption just simplifies the parametrization below and can be easily relaxed to more complex and also correlated multivariate distributions. The only important assumption for the current implementation is that the discretization grid of the different dimensions has the same step size.
[2]:
# number of qubits per dimension to represent the uncertainty
num_uncertainty_qubits = 2
# parameters for considered random distribution
S = 2.0 # initial spot price
vol = 0.4 # volatility of 40%
r = 0.05 # annual interest rate of 4%
T = 40 / 365 # 40 days to maturity
# resulting parameters for log-normal distribution
mu = (r - 0.5 * vol**2) * T + np.log(S)
sigma = vol * np.sqrt(T)
mean = np.exp(mu + sigma**2 / 2)
variance = (np.exp(sigma**2) - 1) * np.exp(2 * mu + sigma**2)
stddev = np.sqrt(variance)
# lowest and highest value considered for the spot price; in between, an equidistant discretization is considered.
low = np.maximum(0, mean - 3 * stddev)
high = mean + 3 * stddev
# map to higher dimensional distribution
# for simplicity assuming dimensions are independent and identically distributed)
dimension = 2
num_qubits = [num_uncertainty_qubits] * dimension
low = low * np.ones(dimension)
high = high * np.ones(dimension)
mu = mu * np.ones(dimension)
cov = sigma**2 * np.eye(dimension)
# construct circuit
u = LogNormalDistribution(num_qubits=num_qubits, mu=mu, sigma=cov, bounds=list(zip(low, high)))
[3]:
# plot PDF of uncertainty model
x = [v[0] for v in u.values]
y = [v[1] for v in u.values]
z = u.probabilities
# z = map(float, z)
# z = list(map(float, z))
resolution = np.array([2**n for n in num_qubits]) * 1j
grid_x, grid_y = np.mgrid[min(x) : max(x) : resolution[0], min(y) : max(y) : resolution[1]]
grid_z = griddata((x, y), z, (grid_x, grid_y))
plt.figure(figsize=(10, 8))
ax = plt.axes(projection="3d")
ax.plot_surface(grid_x, grid_y, grid_z, cmap=plt.cm.Spectral)
ax.set_xlabel("Spot Price $S_T^1$ (\$)", size=15)
ax.set_ylabel("Spot Price $S_T^2$ (\$)", size=15)
ax.set_zlabel("Probability (\%)", size=15)
plt.show()
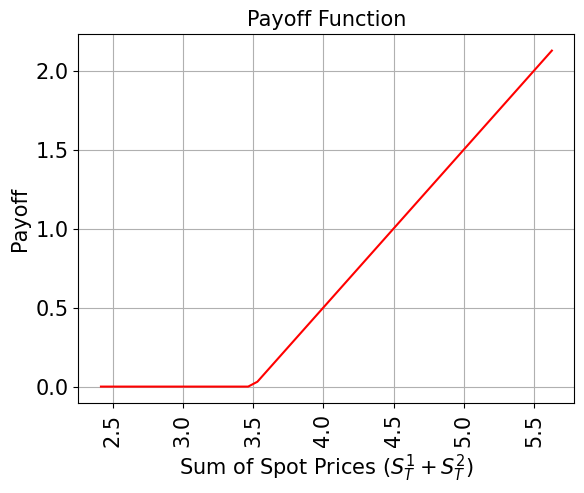
Payoff Function#
The payoff function equals zero as long as the sum of the spot prices at maturity \((S_T^1 + S_T^2)\) is less than the strike price \(K\) and then increases linearly. The implementation first uses a weighted sum operator to compute the sum of the spot prices into an ancilla register, and then uses a comparator, that flips an ancilla qubit from \(\big|0\rangle\) to \(\big|1\rangle\) if \((S_T^1 + S_T^2) \geq K\). This ancilla is used to control the linear part of the payoff function.
The linear part itself is approximated as follows. We exploit the fact that \(\sin^2(y + \pi/4) \approx y + 1/2\) for small \(|y|\). Thus, for a given approximation rescaling factor \(c_\text{approx} \in [0, 1]\) and \(x \in [0, 1]\) we consider
for small \(c_\text{approx}\).
We can easily construct an operator that acts as
using controlled Y-rotations.
Eventually, we are interested in the probability of measuring \(\big|1\rangle\) in the last qubit, which corresponds to \(\sin^2(a*x+b)\). Together with the approximation above, this allows to approximate the values of interest. The smaller we choose \(c_\text{approx}\), the better the approximation. However, since we are then estimating a property scaled by \(c_\text{approx}\), the number of evaluation qubits \(m\) needs to be adjusted accordingly.
For more details on the approximation, we refer to: Quantum Risk Analysis. Woerner, Egger. 2018.
Since the weighted sum operator (in its current implementation) can only sum up integers, we need to map from the original ranges to the representable range to estimate the result, and reverse this mapping before interpreting the result. The mapping essentially corresponds to the affine mapping described in the context of the uncertainty model above.
[4]:
# determine number of qubits required to represent total loss
weights = []
for n in num_qubits:
for i in range(n):
weights += [2**i]
# create aggregation circuit
agg = WeightedAdder(sum(num_qubits), weights)
n_s = agg.num_sum_qubits
n_aux = agg.num_qubits - n_s - agg.num_state_qubits # number of additional qubits
[5]:
# set the strike price (should be within the low and the high value of the uncertainty)
strike_price = 3.5
# map strike price from [low, high] to {0, ..., 2^n-1}
max_value = 2**n_s - 1
low_ = low[0]
high_ = high[0]
mapped_strike_price = (
(strike_price - dimension * low_) / (high_ - low_) * (2**num_uncertainty_qubits - 1)
)
# set the approximation scaling for the payoff function
c_approx = 0.25
# setup piecewise linear objective fcuntion
breakpoints = [0, mapped_strike_price]
slopes = [0, 1]
offsets = [0, 0]
f_min = 0
f_max = 2 * (2**num_uncertainty_qubits - 1) - mapped_strike_price
basket_objective = LinearAmplitudeFunction(
n_s,
slopes,
offsets,
domain=(0, max_value),
image=(f_min, f_max),
rescaling_factor=c_approx,
breakpoints=breakpoints,
)
[6]:
# define overall multivariate problem
qr_state = QuantumRegister(u.num_qubits, "state") # to load the probability distribution
qr_obj = QuantumRegister(1, "obj") # to encode the function values
ar_sum = AncillaRegister(n_s, "sum") # number of qubits used to encode the sum
ar = AncillaRegister(max(n_aux, basket_objective.num_ancillas), "work") # additional qubits
objective_index = u.num_qubits
basket_option = QuantumCircuit(qr_state, qr_obj, ar_sum, ar)
basket_option.append(u, qr_state)
basket_option.append(agg, qr_state[:] + ar_sum[:] + ar[:n_aux])
basket_option.append(basket_objective, ar_sum[:] + qr_obj[:] + ar[: basket_objective.num_ancillas])
print(basket_option.draw())
print("objective qubit index", objective_index)
┌───────┐┌────────┐
state_0: ┤0 ├┤0 ├──────
│ ││ │
state_1: ┤1 ├┤1 ├──────
│ P(X) ││ │
state_2: ┤2 ├┤2 ├──────
│ ││ │
state_3: ┤3 ├┤3 ├──────
└───────┘│ │┌────┐
obj: ─────────┤ ├┤3 ├
│ ││ │
sum_0: ─────────┤4 adder ├┤0 ├
│ ││ │
sum_1: ─────────┤5 ├┤1 ├
│ ││ │
sum_2: ─────────┤6 ├┤2 F ├
│ ││ │
work_0: ─────────┤7 ├┤4 ├
│ ││ │
work_1: ─────────┤8 ├┤5 ├
│ ││ │
work_2: ─────────┤9 ├┤6 ├
└────────┘└────┘
objective qubit index 4
[7]:
# plot exact payoff function (evaluated on the grid of the uncertainty model)
x = np.linspace(sum(low), sum(high))
y = np.maximum(0, x - strike_price)
plt.plot(x, y, "r-")
plt.grid()
plt.title("Payoff Function", size=15)
plt.xlabel("Sum of Spot Prices ($S_T^1 + S_T^2)$", size=15)
plt.ylabel("Payoff", size=15)
plt.xticks(size=15, rotation=90)
plt.yticks(size=15)
plt.show()
[8]:
# evaluate exact expected value
sum_values = np.sum(u.values, axis=1)
exact_value = np.dot(
u.probabilities[sum_values >= strike_price],
sum_values[sum_values >= strike_price] - strike_price,
)
print("exact expected value:\t%.4f" % exact_value)
exact expected value: 0.4870
Evaluate Expected Payoff#
We first verify the quantum circuit by simulating it and analyzing the resulting probability to measure the \(|1\rangle\) state in the objective qubit.
[9]:
num_state_qubits = basket_option.num_qubits - basket_option.num_ancillas
print("state qubits: ", num_state_qubits)
transpiled = transpile(basket_option, basis_gates=["u", "cx"])
print("circuit width:", transpiled.width())
print("circuit depth:", transpiled.depth())
state qubits: 5
circuit width: 11
circuit depth: 415
[10]:
basket_option_measure = basket_option.measure_all(inplace=False)
sampler = Sampler()
job = sampler.run(basket_option_measure)
[11]:
# evaluate the result
value = 0
probabilities = job.result().quasi_dists[0].binary_probabilities()
for i, prob in probabilities.items():
if prob > 1e-4 and i[-num_state_qubits:][0] == "1":
value += prob
# map value to original range
mapped_value = (
basket_objective.post_processing(value) / (2**num_uncertainty_qubits - 1) * (high_ - low_)
)
print("Exact Operator Value: %.4f" % value)
print("Mapped Operator value: %.4f" % mapped_value)
print("Exact Expected Payoff: %.4f" % exact_value)
Exact Operator Value: 0.3672
Mapped Operator value: 0.3441
Exact Expected Payoff: 0.4870
Next we use amplitude estimation to estimate the expected payoff.
[12]:
# set target precision and confidence level
epsilon = 0.01
alpha = 0.05
problem = EstimationProblem(
state_preparation=basket_option,
objective_qubits=[objective_index],
post_processing=basket_objective.post_processing,
)
# construct amplitude estimation
ae = IterativeAmplitudeEstimation(
epsilon_target=epsilon, alpha=alpha, sampler=Sampler(run_options={"shots": 100, "seed": 75})
)
[13]:
result = ae.estimate(problem)
[14]:
conf_int = (
np.array(result.confidence_interval_processed)
/ (2**num_uncertainty_qubits - 1)
* (high_ - low_)
)
print("Exact value: \t%.4f" % exact_value)
print(
"Estimated value: \t%.4f"
% (result.estimation_processed / (2**num_uncertainty_qubits - 1) * (high_ - low_))
)
print("Confidence interval:\t[%.4f, %.4f]" % tuple(conf_int))
Exact value: 0.4870
Estimated value: 0.4945
Confidence interval: [0.4821, 0.5069]
[15]:
import tutorial_magics
%qiskit_version_table
%qiskit_copyright
Version Information
| Software | Version |
|---|---|
qiskit | 1.0.1 |
qiskit_aer | 0.13.3 |
qiskit_algorithms | 0.3.0 |
qiskit_finance | 0.4.1 |
| System information | |
| Python version | 3.8.18 |
| OS | Linux |
| Thu Feb 29 03:06:38 2024 UTC | |
This code is a part of a Qiskit project
© Copyright IBM 2017, 2024.
This code is licensed under the Apache License, Version 2.0. You may
obtain a copy of this license in the LICENSE.txt file in the root directory
of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
Any modifications or derivative works of this code must retain this
copyright notice, and modified files need to carry a notice indicating
that they have been altered from the originals.
[ ]: