Note
This page was generated from docs/tutorials/05_bull_spread_pricing.ipynb.
Pricing Bull Spreads#
Introduction#
Suppose a bull spread with strike prices \(K_1 < K_2\) and an underlying asset whose spot price at maturity \(S_T\) follows a given random distribution. The corresponding payoff function is defined as:
In the following, a quantum algorithm based on amplitude estimation is used to estimate the expected payoff, i.e., the fair price before discounting, for the option:
as well as the corresponding \(\Delta\), i.e., the derivative of the option price with respect to the spot price, defined as:
The approximation of the objective function and a general introduction to option pricing and risk analysis on quantum computers are given in the following papers:
[1]:
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
from qiskit_algorithms import IterativeAmplitudeEstimation, EstimationProblem
from qiskit.circuit.library import LinearAmplitudeFunction
from qiskit_aer.primitives import Sampler
from qiskit_finance.circuit.library import LogNormalDistribution
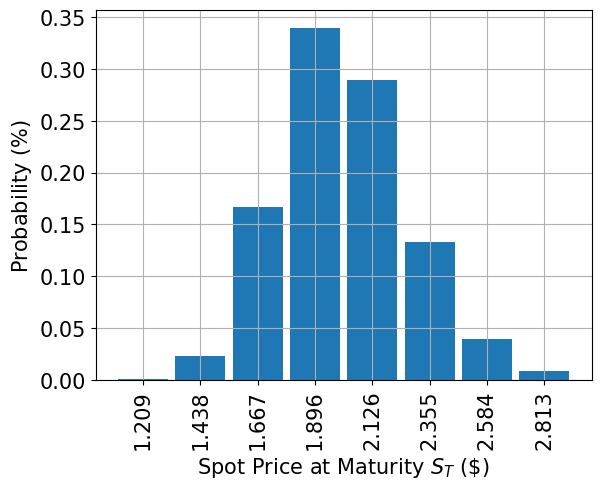
Uncertainty Model#
We construct a circuit to load a log-normal random distribution into a quantum state. The distribution is truncated to a given interval \([\text{low}, \text{high}]\) and discretized using \(2^n\) grid points, where \(n\) denotes the number of qubits used. The unitary operator corresponding to the circuit implements the following:
where \(p_i\) denote the probabilities corresponding to the truncated and discretized distribution and where \(i\) is mapped to the right interval using the affine map:
[2]:
# number of qubits to represent the uncertainty
num_uncertainty_qubits = 3
# parameters for considered random distribution
S = 2.0 # initial spot price
vol = 0.4 # volatility of 40%
r = 0.05 # annual interest rate of 4%
T = 40 / 365 # 40 days to maturity
# resulting parameters for log-normal distribution
mu = (r - 0.5 * vol**2) * T + np.log(S)
sigma = vol * np.sqrt(T)
mean = np.exp(mu + sigma**2 / 2)
variance = (np.exp(sigma**2) - 1) * np.exp(2 * mu + sigma**2)
stddev = np.sqrt(variance)
# lowest and highest value considered for the spot price; in between, an equidistant discretization is considered.
low = np.maximum(0, mean - 3 * stddev)
high = mean + 3 * stddev
# construct circuit for uncertainty model
uncertainty_model = LogNormalDistribution(
num_uncertainty_qubits, mu=mu, sigma=sigma**2, bounds=(low, high)
)
[3]:
# plot probability distribution
x = uncertainty_model.values
y = uncertainty_model.probabilities
plt.bar(x, y, width=0.2)
plt.xticks(x, size=15, rotation=90)
plt.yticks(size=15)
plt.grid()
plt.xlabel("Spot Price at Maturity $S_T$ (\$)", size=15)
plt.ylabel("Probability ($\%$)", size=15)
plt.show()
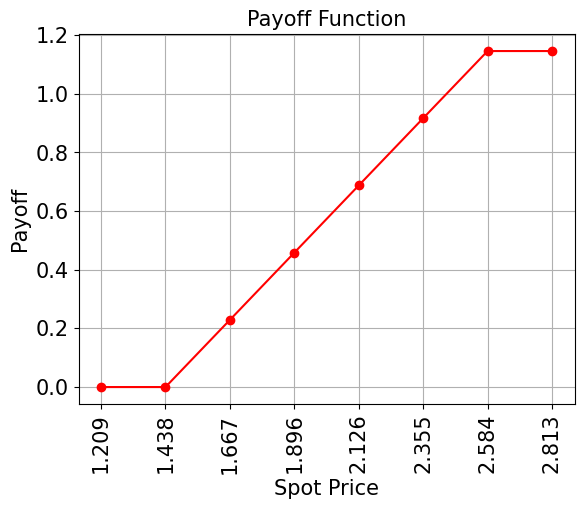
Payoff Function#
The payoff function equals zero as long as the spot price at maturity \(S_T\) is less than the strike price \(K_1\), then increases linearly, and is bounded by \(K_2\). The implementation uses two comparators, that flip an ancilla qubit each from \(\big|0\rangle\) to \(\big|1\rangle\) if \(S_T \geq K_1\) and \(S_T \leq K_2\), and these ancillas are used to control the linear part of the payoff function.
The linear part itself is then approximated as follows. We exploit the fact that \(\sin^2(y + \pi/4) \approx y + 1/2\) for small \(|y|\). Thus, for a given approximation rescaling factor \(c_\text{approx} \in [0, 1]\) and \(x \in [0, 1]\) we consider
for small \(c_\text{approx}\).
We can easily construct an operator that acts as
using controlled Y-rotations.
Eventually, we are interested in the probability of measuring \(\big|1\rangle\) in the last qubit, which corresponds to \(\sin^2(a*x+b)\). Together with the approximation above, this allows to approximate the values of interest. The smaller we choose \(c_\text{approx}\), the better the approximation. However, since we are then estimating a property scaled by \(c_\text{approx}\), the number of evaluation qubits \(m\) needs to be adjusted accordingly.
For more details on the approximation, we refer to: Quantum Risk Analysis. Woerner, Egger. 2018.
[4]:
# set the strike price (should be within the low and the high value of the uncertainty)
strike_price_1 = 1.438
strike_price_2 = 2.584
# set the approximation scaling for the payoff function
rescaling_factor = 0.25
# setup piecewise linear objective fcuntion
breakpoints = [low, strike_price_1, strike_price_2]
slopes = [0, 1, 0]
offsets = [0, 0, strike_price_2 - strike_price_1]
f_min = 0
f_max = strike_price_2 - strike_price_1
bull_spread_objective = LinearAmplitudeFunction(
num_uncertainty_qubits,
slopes,
offsets,
domain=(low, high),
image=(f_min, f_max),
breakpoints=breakpoints,
rescaling_factor=rescaling_factor,
)
# construct A operator for QAE for the payoff function by
# composing the uncertainty model and the objective
bull_spread = bull_spread_objective.compose(uncertainty_model, front=True)
[5]:
# plot exact payoff function (evaluated on the grid of the uncertainty model)
x = uncertainty_model.values
y = np.minimum(np.maximum(0, x - strike_price_1), strike_price_2 - strike_price_1)
plt.plot(x, y, "ro-")
plt.grid()
plt.title("Payoff Function", size=15)
plt.xlabel("Spot Price", size=15)
plt.ylabel("Payoff", size=15)
plt.xticks(x, size=15, rotation=90)
plt.yticks(size=15)
plt.show()
[6]:
# evaluate exact expected value (normalized to the [0, 1] interval)
exact_value = np.dot(uncertainty_model.probabilities, y)
exact_delta = sum(
uncertainty_model.probabilities[np.logical_and(x >= strike_price_1, x <= strike_price_2)]
)
print("exact expected value:\t%.4f" % exact_value)
print("exact delta value: \t%.4f" % exact_delta)
exact expected value: 0.5695
exact delta value: 0.9291
Evaluate Expected Payoff#
[7]:
# set target precision and confidence level
epsilon = 0.01
alpha = 0.05
problem = EstimationProblem(
state_preparation=bull_spread,
objective_qubits=[num_uncertainty_qubits],
post_processing=bull_spread_objective.post_processing,
)
# construct amplitude estimation
ae = IterativeAmplitudeEstimation(
epsilon_target=epsilon, alpha=alpha, sampler=Sampler(run_options={"shots": 100, "seed": 75})
)
[8]:
result = ae.estimate(problem)
[9]:
conf_int = np.array(result.confidence_interval_processed)
print("Exact value: \t%.4f" % exact_value)
print("Estimated value:\t%.4f" % result.estimation_processed)
print("Confidence interval: \t[%.4f, %.4f]" % tuple(conf_int))
Exact value: 0.5695
Estimated value: 0.5686
Confidence interval: [0.5610, 0.5763]
Evaluate Delta#
The Delta is a bit simpler to evaluate than the expected payoff. Similarly to the expected payoff, we use comparator circuits and ancilla qubits to identify the cases where \(K_1 \leq S_T \leq K_2\). However, since we are only interested in the probability of this condition being true, we can directly use an ancilla qubit as the objective qubit in amplitude estimation without any further approximation.
[10]:
# setup piecewise linear objective fcuntion
breakpoints = [low, strike_price_1, strike_price_2]
slopes = [0, 0, 0]
offsets = [0, 1, 0]
f_min = 0
f_max = 1
bull_spread_delta_objective = LinearAmplitudeFunction(
num_uncertainty_qubits,
slopes,
offsets,
domain=(low, high),
image=(f_min, f_max),
breakpoints=breakpoints,
) # no approximation necessary, hence no rescaling factor
# construct the A operator by stacking the uncertainty model and payoff function together
bull_spread_delta = bull_spread_delta_objective.compose(uncertainty_model, front=True)
[11]:
# set target precision and confidence level
epsilon = 0.01
alpha = 0.05
problem = EstimationProblem(
state_preparation=bull_spread_delta, objective_qubits=[num_uncertainty_qubits]
)
# construct amplitude estimation
ae_delta = IterativeAmplitudeEstimation(
epsilon_target=epsilon, alpha=alpha, sampler=Sampler(run_options={"shots": 100, "seed": 75})
)
[12]:
result_delta = ae_delta.estimate(problem)
[13]:
conf_int = np.array(result_delta.confidence_interval)
print("Exact delta: \t%.4f" % exact_delta)
print("Estimated value:\t%.4f" % result_delta.estimation)
print("Confidence interval: \t[%.4f, %.4f]" % tuple(conf_int))
Exact delta: 0.9291
Estimated value: 0.9290
Confidence interval: [0.9269, 0.9312]
[14]:
import tutorial_magics
%qiskit_version_table
%qiskit_copyright
Version Information
| Software | Version |
|---|---|
qiskit | 1.0.1 |
qiskit_algorithms | 0.3.0 |
qiskit_aer | 0.13.3 |
qiskit_finance | 0.4.1 |
| System information | |
| Python version | 3.8.18 |
| OS | Linux |
| Thu Feb 29 03:06:30 2024 UTC | |
This code is a part of a Qiskit project
© Copyright IBM 2017, 2024.
This code is licensed under the Apache License, Version 2.0. You may
obtain a copy of this license in the LICENSE.txt file in the root directory
of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
Any modifications or derivative works of this code must retain this
copyright notice, and modified files need to carry a notice indicating
that they have been altered from the originals.
[ ]: