Note
Cette page a été générée à partir de docs/tutorials/05_uploading_program.ipynb.
Sauvegarder, Charger les modèles Qiskit Machine Learning et Entraînement Continu#
Dans ce tutoriel nous montrerons comment enregistrer et charger les modèles d’apprentissage automatique Qiskit. La fonctionalité de sauvegarde d’un modèle est très importante, surtout lorsque beaucoup de temps est investi dans l’entraînment d’un modèle sur un véritable système. De plus, nous montrerons comment reprendre l’entraînment du modèle précédemment enregistré.
Dans ce tutoriel, nous allons apprendre à :
Générer un simple ensemble de données, le diviser en ensembles d’apprentissage et de test, et les représenter graphiquement
Entraînez et sauvegarder un modèle
Charger un modèle sauvegardé et reprendre l’apprentissage
Évaluer la performance des modèles
Modèles hybrides PyTorch
Tout d’abord, nous commençons par les importations requises. Nous utiliserons beaucoup SciKit-Learn pour l’étape de préparation des données. Dans la cellule suivante, nous définissons également une graine aléatoire à des fins de reproductibilité.
[1]:
import matplotlib.pyplot as plt
import numpy as np
from qiskit.circuit.library import RealAmplitudes
from qiskit.primitives import Sampler
from qiskit_algorithms.optimizers import COBYLA
from qiskit_algorithms.utils import algorithm_globals
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder, MinMaxScaler
from qiskit_machine_learning.algorithms.classifiers import VQC
from IPython.display import clear_output
algorithm_globals.random_seed = 42
Nous allons utiliser deux simulateurs quantiques, plus particulièrement, deux instances de la primitive Sampler. Nous débuterons la phase apprentissage sur la première, puis reprendrons l’apprentissage sur la deuxième. L’approche illustrée dans ce tutoriel peut être utilisée pour entraîner un modèle sur un véritable système disponible sur le cloud, puis réutiliser le modèle pour un simulateur local.
[2]:
sampler1 = Sampler()
sampler2 = Sampler()
1. Préparer un ensemble de données#
L’étape suivante consiste à préparer un ensemble de données. Ici, nous générons des données de la même façon que dans d’autres tutoriels. La différence est que nous appliquons certaines transformations aux données générées. Nous générons 40 échantillons, chaque échantillon a 2 variables, donc nos variables sont un ensemble de forme (40, 2). L’étiquetage est obtenu en additionnant les variables par colonnes et si la somme est supérieure à 1, alors cet échantillon est marqué comme 1 et 0 autrement.
[3]:
num_samples = 40
num_features = 2
features = 2 * algorithm_globals.random.random([num_samples, num_features]) - 1
labels = 1 * (np.sum(features, axis=1) >= 0) # in { 0, 1}
Ensuite, nous réduisons nos variables à [0, 1] en appliquant MinMaxScaler de SciKit-Learn. La convergence de l’entraînement du modèle est meilleure lorsque cette transformation est appliquée.
[4]:
features = MinMaxScaler().fit_transform(features)
features.shape
[4]:
(40, 2)
Examinons les variables des premiers 5 échantillons de notre ensemble de données, après la transformation.
[5]:
features[0:5, :]
[5]:
array([[0.79067335, 0.44566143],
[0.88072937, 0.7126244 ],
[0.06741233, 1. ],
[0.7770372 , 0.80422817],
[0.10351936, 0.45754615]])
We choose VQC or Variational Quantum Classifier as a model we will train. This model, by default, takes one-hot encoded labels, so we have to transform the labels that are in the set of {0, 1} into one-hot representation. We employ SciKit-Learn for this transformation as well. Please note that the input array must be reshaped to (num_samples, 1) first. The OneHotEncoder encoder does not work with 1D arrays and our labels is a 1D array. In this case a user must decide either an
array has only one feature(our case!) or has one sample. Also, by default the encoder returns sparse arrays, but for dataset plotting it is easier to have dense arrays, so we set sparse to False.
[6]:
labels = OneHotEncoder(sparse_output=False).fit_transform(labels.reshape(-1, 1))
labels.shape
[6]:
(40, 2)
Examinons l’étiquetage des premiers 5 échantillons de l’ensemble de données. Les étiquettes devraient être encodées one-hot.
[7]:
labels[0:5, :]
[7]:
array([[0., 1.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.]])
Maintenant, nous divisons notre ensemble de données en deux parties : un ensemble de données d’entraînement et un ensemble de données de test. En règle générale, 80 % d’un ensemble de données devrait être dédié à l’entraînement et 20 % au test. Notre ensemble de données d’entraînement a 30 échantillons. L’ensemble de données de test ne devrait être utilisé qu’une seule fois, lorsqu’un modèle est formé pour vérifier comment le modèle se comporte sur les données nouvelles. Nous utilisons train_test_split de SciKit-Learn.
[8]:
train_features, test_features, train_labels, test_labels = train_test_split(
features, labels, train_size=30, random_state=algorithm_globals.random_seed
)
train_features.shape
[8]:
(30, 2)
Maintenant, il est temps de voir à quoi ressemble notre ensemble de données. Représentons le graphiquement.
[9]:
def plot_dataset():
plt.scatter(
train_features[np.where(train_labels[:, 0] == 0), 0],
train_features[np.where(train_labels[:, 0] == 0), 1],
marker="o",
color="b",
label="Label 0 train",
)
plt.scatter(
train_features[np.where(train_labels[:, 0] == 1), 0],
train_features[np.where(train_labels[:, 0] == 1), 1],
marker="o",
color="g",
label="Label 1 train",
)
plt.scatter(
test_features[np.where(test_labels[:, 0] == 0), 0],
test_features[np.where(test_labels[:, 0] == 0), 1],
marker="o",
facecolors="w",
edgecolors="b",
label="Label 0 test",
)
plt.scatter(
test_features[np.where(test_labels[:, 0] == 1), 0],
test_features[np.where(test_labels[:, 0] == 1), 1],
marker="o",
facecolors="w",
edgecolors="g",
label="Label 1 test",
)
plt.legend(bbox_to_anchor=(1.05, 1), loc="upper left", borderaxespad=0.0)
plt.plot([1, 0], [0, 1], "--", color="black")
plot_dataset()
plt.show()
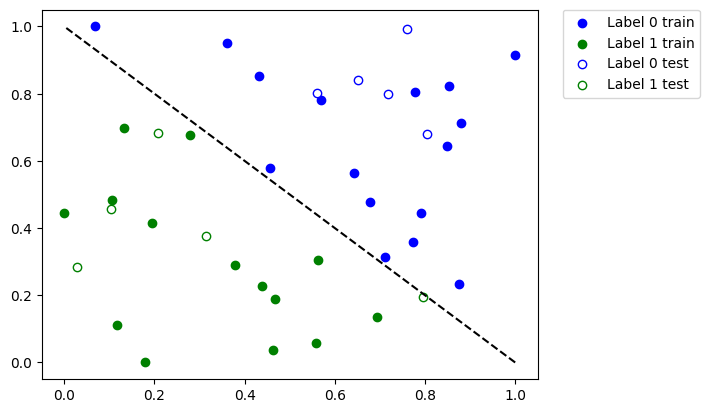
Sur le graphique ci-dessus, nous remarquons :
Les points bleus solides sont les échantillons de l’ensemble de données d’entraînement, annotés
0Les points bleus vides sont les échantillons de l’ensemble de données de test, annotés
0Les points verts solides sont les échantillons de l’ensemble de données d’entraînement, annotés
1Les points verts vides sont les échantillons de l’ensemble de données de test, annotés
1
Nous allons former notre modèle à l’aide de points solides et le vérifier à l’aide de points vides.
2. Entraîner un modèle et le sauvegarder#
Nous formerons notre modèle en deux étapes. Pour la première étape, nous formons notre modèle en 20 itérations.
[10]:
maxiter = 20
Créez un tableau vide pour le rappel afin de stocker les valeurs de la fonction objectif.
[11]:
objective_values = []
Nous réutiliserons une fonction de rappel à partir du tutoriel Classificateur de réseau de neurones & Regressor pour tracer la valeur de l’itération par rapport à la valeur de la fonction objectif avec quelques petits tweaks pour tracer des valeurs objectives à chaque étape.
[12]:
# callback function that draws a live plot when the .fit() method is called
def callback_graph(_, objective_value):
clear_output(wait=True)
objective_values.append(objective_value)
plt.title("Objective function value against iteration")
plt.xlabel("Iteration")
plt.ylabel("Objective function value")
stage1_len = np.min((len(objective_values), maxiter))
stage1_x = np.linspace(1, stage1_len, stage1_len)
stage1_y = objective_values[:stage1_len]
stage2_len = np.max((0, len(objective_values) - maxiter))
stage2_x = np.linspace(maxiter, maxiter + stage2_len - 1, stage2_len)
stage2_y = objective_values[maxiter : maxiter + stage2_len]
plt.plot(stage1_x, stage1_y, color="orange")
plt.plot(stage2_x, stage2_y, color="purple")
plt.show()
plt.rcParams["figure.figsize"] = (12, 6)
Comme mentionné ci-dessus, nous formons un modèle ` ` VQC ` ` et définissez ` ` COBYLA ` ` en tant qu’optimiseur avec une valeur choisie du paramètre ` ` maxiter ` `. Ensuite, nous évaluons les performances du modèle pour voir à quel point il a été formé. Ensuite, nous sauvegartons ce modèle pour un fichier. Au cours de la deuxième étape, nous chargerons ce modèle et nous continuerons à travailler avec lui.
Ici, nous construisons manuellement un ansatz pour fixer un point initial où commencer l’optimisation à partir de.
[13]:
original_optimizer = COBYLA(maxiter=maxiter)
ansatz = RealAmplitudes(num_features)
initial_point = np.asarray([0.5] * ansatz.num_parameters)
Nous créons un modèle et nous fixons un échantillonneur au premier échantillonneur que nous avons créé précédemment.
[14]:
original_classifier = VQC(
ansatz=ansatz, optimizer=original_optimizer, callback=callback_graph, sampler=sampler1
)
Il est maintenant temps de former le modèle.
[15]:
original_classifier.fit(train_features, train_labels)
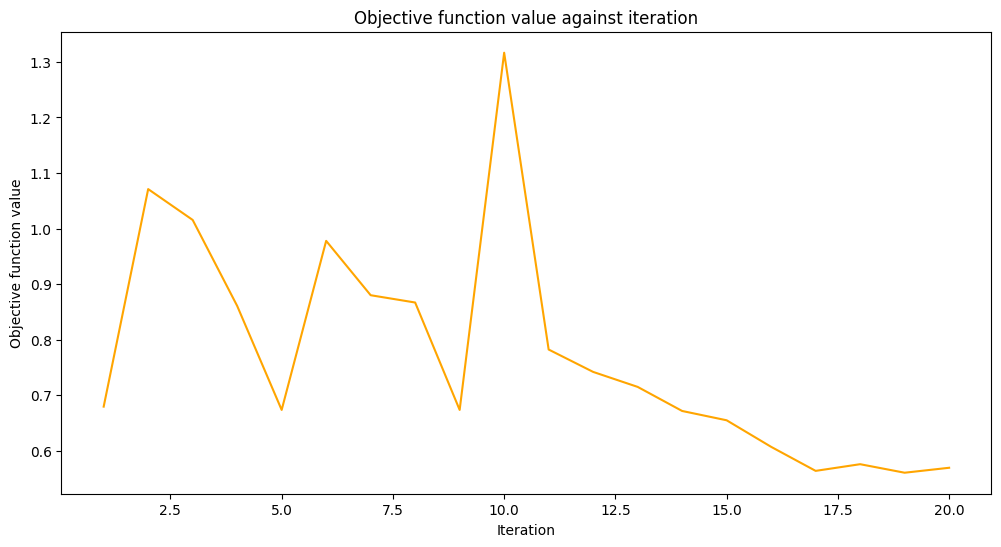
[15]:
<qiskit_machine_learning.algorithms.classifiers.vqc.VQC at 0x7fb74126db20>
Voyons à quel point notre modèle fonctionne bien après la première étape de la formation.
[16]:
print("Train score", original_classifier.score(train_features, train_labels))
print("Test score ", original_classifier.score(test_features, test_labels))
Train score 0.8333333333333334
Test score 0.8
Next, we save the model. You may choose any file name you want. Please note that the save method does not append an extension if it is not specified in the file name.
[17]:
original_classifier.save("vqc_classifier.model")
3. Charger un modèle et poursuivre la formation#
To load a model a user have to call a class method load of the corresponding model class. In our case it is VQC. We pass the same file name we used in the previous section where we saved our model.
[18]:
loaded_classifier = VQC.load("vqc_classifier.model")
Next, we want to alter the model in a way it can be trained further and on another simulator. To do so, we set the warm_start property. When it is set to True and fit() is called again the model uses weights from previous fit to start a new fit. We also set the sampler property of the underlying network to the second instance of the Sampler primitive we created in the beginning of the tutorial. Finally, we create and set a new optimizer with maxiter is set to 80, so
the total number of iterations is 100.
[19]:
loaded_classifier.warm_start = True
loaded_classifier.neural_network.sampler = sampler2
loaded_classifier.optimizer = COBYLA(maxiter=80)
Now we continue training our model from the state we finished in the previous section.
[20]:
loaded_classifier.fit(train_features, train_labels)
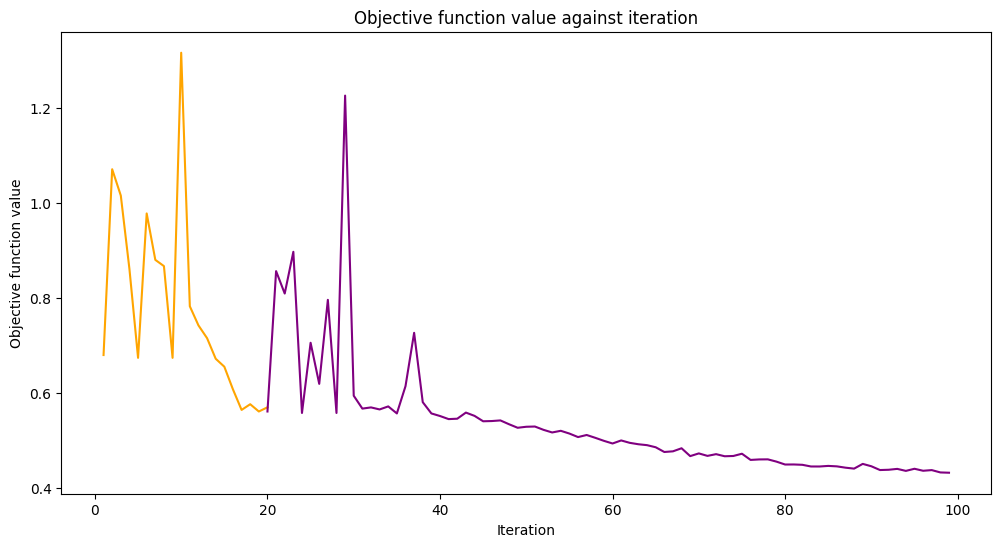
[20]:
<qiskit_machine_learning.algorithms.classifiers.vqc.VQC at 0x7fb7411cb760>
[21]:
print("Train score", loaded_classifier.score(train_features, train_labels))
print("Test score", loaded_classifier.score(test_features, test_labels))
Train score 0.9
Test score 0.8
Let’s see which data points were misclassified. First, we call predict to infer predicted values from the training and test features.
[22]:
train_predicts = loaded_classifier.predict(train_features)
test_predicts = loaded_classifier.predict(test_features)
Plot the whole dataset and the highlight the points that were classified incorrectly.
[23]:
# return plot to default figsize
plt.rcParams["figure.figsize"] = (6, 4)
plot_dataset()
# plot misclassified data points
plt.scatter(
train_features[np.all(train_labels != train_predicts, axis=1), 0],
train_features[np.all(train_labels != train_predicts, axis=1), 1],
s=200,
facecolors="none",
edgecolors="r",
linewidths=2,
)
plt.scatter(
test_features[np.all(test_labels != test_predicts, axis=1), 0],
test_features[np.all(test_labels != test_predicts, axis=1), 1],
s=200,
facecolors="none",
edgecolors="r",
linewidths=2,
)
[23]:
<matplotlib.collections.PathCollection at 0x7fb6e04c2eb0>
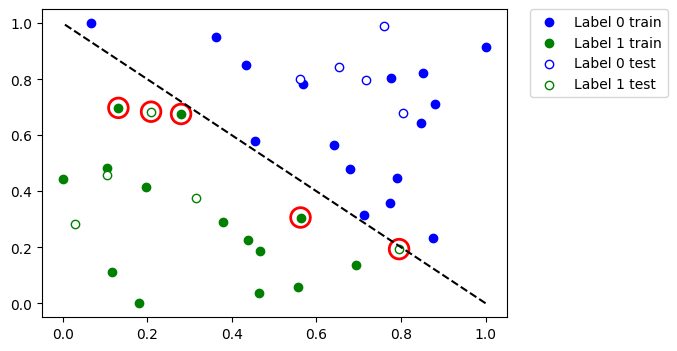
So, if you have a large dataset or a large model you can train it in multiple steps as shown in this tutorial.
4. Modèles hybrides PyTorch#
To save and load hybrid models, when using the TorchConnector, follow the PyTorch recommendations of saving and loading the models. For more details please refer to the PyTorch Connector tutorial where a short snippet shows how to do it.
Take a look at this pseudo-like code to get the idea:
# create a QNN and a hybrid model
qnn = create_qnn()
model = Net(qnn)
# ... train the model ...
# save the model
torch.save(model.state_dict(), "model.pt")
# create a new model
new_qnn = create_qnn()
loaded_model = Net(new_qnn)
loaded_model.load_state_dict(torch.load("model.pt"))
[24]:
import qiskit.tools.jupyter
%qiskit_version_table
%qiskit_copyright
Version Information
| Qiskit Software | Version |
|---|---|
qiskit-terra | 0.25.0 |
qiskit-aer | 0.13.0 |
qiskit-machine-learning | 0.7.0 |
| System information | |
| Python version | 3.8.13 |
| Python compiler | Clang 12.0.0 |
| Python build | default, Oct 19 2022 17:54:22 |
| OS | Darwin |
| CPUs | 10 |
| Memory (Gb) | 64.0 |
| Mon Jun 12 11:51:03 2023 IST | |
This code is a part of Qiskit
© Copyright IBM 2017, 2023.
This code is licensed under the Apache License, Version 2.0. You may
obtain a copy of this license in the LICENSE.txt file in the root directory
of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
Any modifications or derivative works of this code must retain this
copyright notice, and modified files need to carry a notice indicating
that they have been altered from the originals.